
K8s环境中部署各种开发应用服务(四 )Redis!!!
Redis来了
有状态服务的准备工作都做好了
终于终于终于,来到了这一步
这篇我们来在K8s环境中启动一个3主3从的Redis集群服务
开始
直接进入Kubernetes Dashboard 用导入YAML来操作
找到上一篇创建的redis这个命名空间
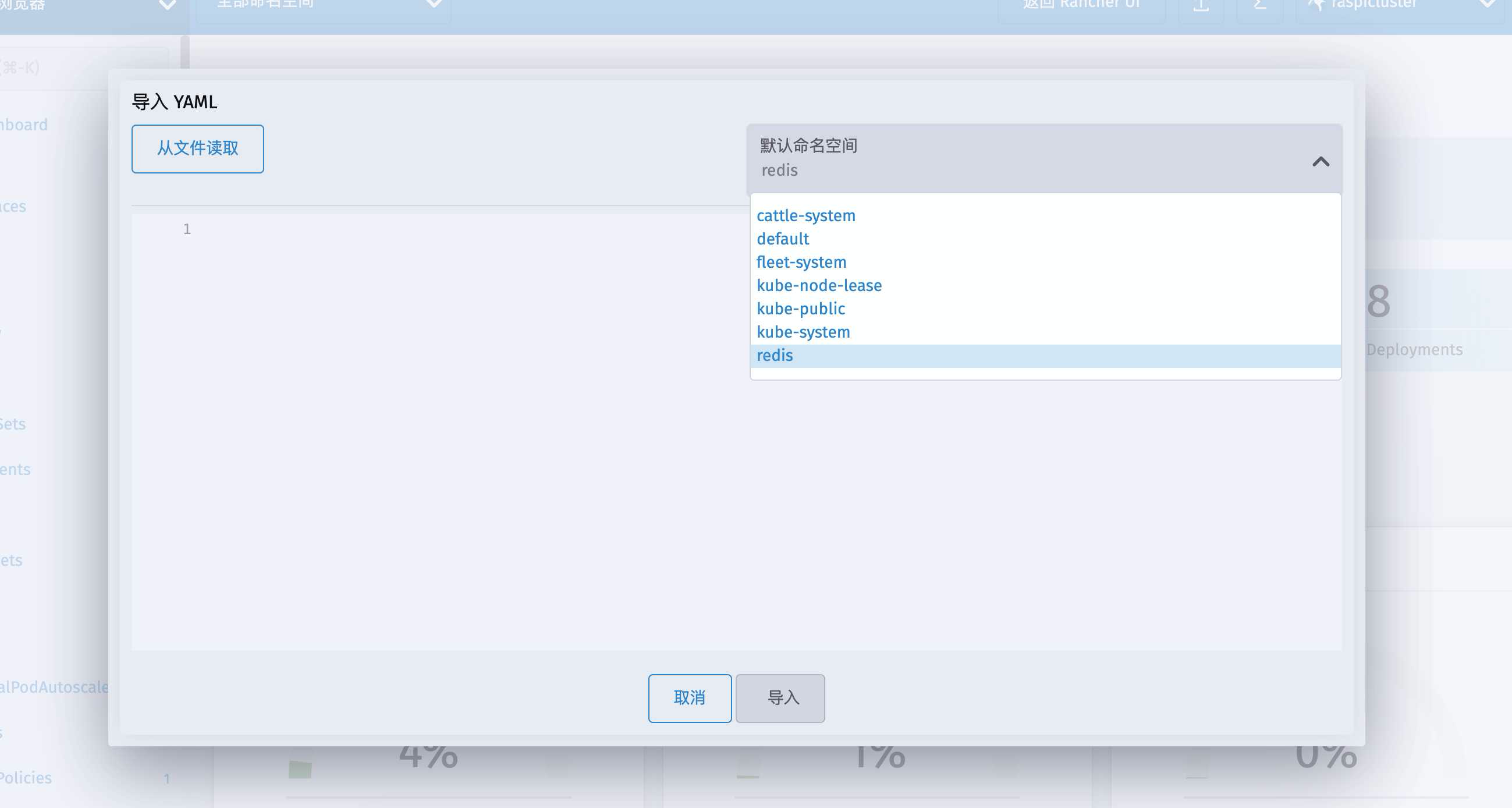
然后我们一步一步来
配置文件的映射(ConfigMap)
先做一个配置文件的映射(ConfigMap)出来
输入下面的内容去导入
apiVersion: v1
data:
redis.conf: |-
port 6379
cluster-enabled yes
cluster-require-full-coverage no
cluster-config-file /data/nodes.conf
cluster-node-timeout 5000
cluster-migration-barrier 1
appendonly yes
save 900 1
save 300 10
save 60 10000
protected-mode no
update-node.sh: |-
#!/bin/sh
REDIS_NODES="/data/nodes.conf"
sed -i -e "/myself/ s/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}/{POD_IP}/"{REDIS_NODES}
exec "$@"
kind: ConfigMap
metadata:
name: redis-cluster
namespace: redis
说明一下
这里创建了一个ConfigMap名叫redis-cluster
这是一个配置文件的映射,用来给后面继续创建任务(Deployment或StatefulSet)来使用的。其中直接输入来创建了两个文件(redis.conf和update-node.sh)
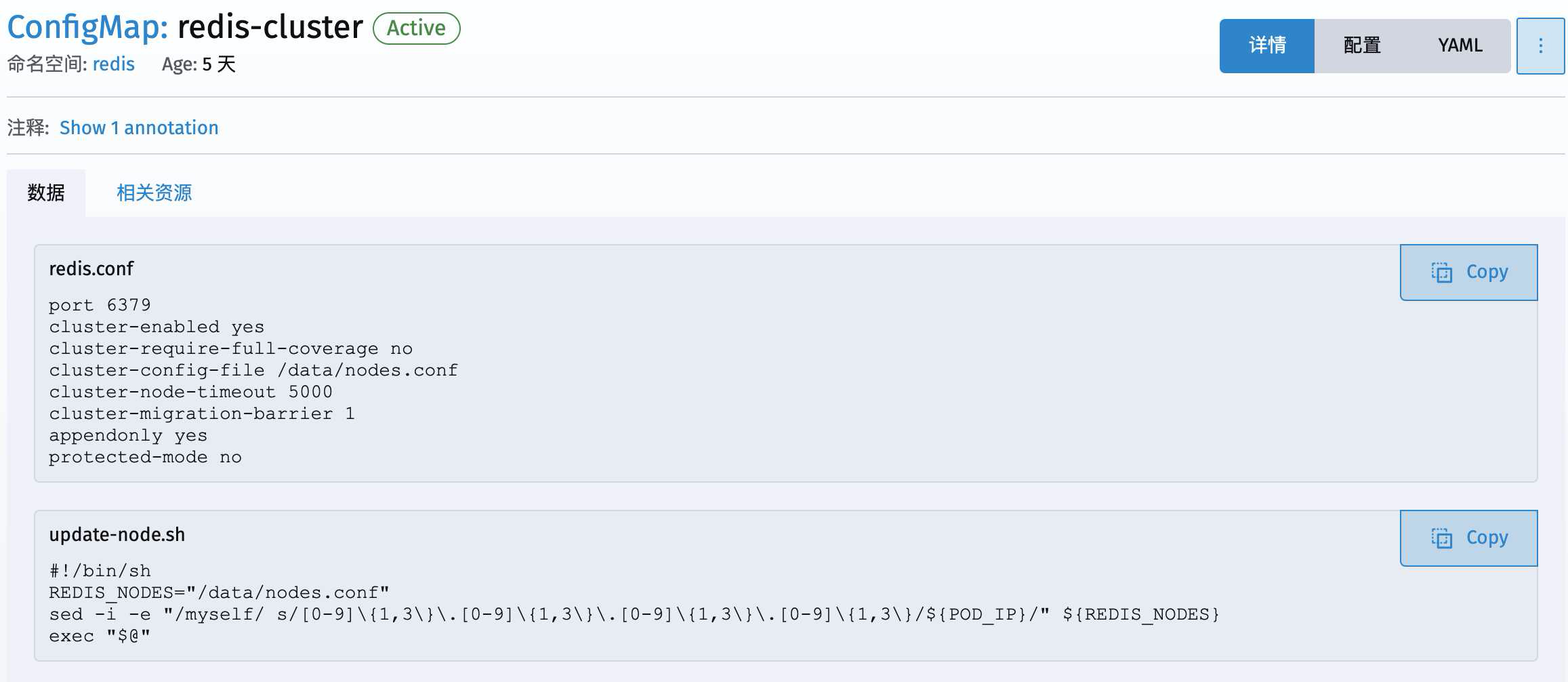
redis.conf
其内容就是redis启动时的一些配置参数,像端口号(port)、节点响应最大时长(cluster-node-timeout)以及是否开启集群功能(cluster-enabled)等等,这些内容和正常部署redis用到的一样。
同时还额外使用了一个配置文件cluster-config-file /data/nodes.conf
此处的/data/nodes.conf内容是通过另一个配置向其写入的当前redis节点的IP地址等信息,用于redis在创建集群时使用的
——特别注意如果没有这个nodes.conf文件去记录podIP 会给后面redis集群运行的时候留下坑
在文章的最后面会现身说法复现一下这个坑
update-node.sh
这里的内容可以看到就是一个执行脚本,在redis节点启动的时候把当前的IP地址写进/data/nodes.conf里面去,其中还额外使用了个环境变量POD_IP,这个是哪儿来的在后面会出现
下一步,来给控制Redis任务的StatefulSet部署一个Headless Service
关于K8s的Service相关详情可以参考下面这个文章
详解k8s 4种类型Service
配置Headless Service
突如其来的科普
简单介绍一下4中Service分别是干嘛的
ClusterIP的service,就是服务于节点,也就是集群内部节点间通信使用的网络服务,如果不希望当前的应用直接暴露给集群外部,就用这个。这个service有一个Cluster-IP,具体实现原理依靠kubeproxy组件,通过iptables或是ipvs实现
NodePort,用于集群外业务访问,这也是引导外部流量到你的服务的最原始方式。Kubernetes会自动或者由人工手动给节点分配一个对外端口
LoadBalancer类型的service 是可以实现集群外部访问服务的另外一种解决方案,也是暴露服务到 internet 的标准方式。这主要用于云厂商提供的服务中,通过云厂商提供的负载均衡服务来支持,最终会提供给使用LoadBalancer的服务一个专门的对外暴露的IP地址
ExternalName是将服务映射到了DNS 名称,而不是IP地址。这样就可以通过DNS服务返回CNAME记录将外部服务映射到内部服务,实现集群外部访问以及服务之间跨命名空间的访问
最后回到Headless Service
Headless Service 其实也是用于集群内部通信用的服务,这个目的和ClusterIP是一样的
但是我们的ClusterIP工作起来是通过iptables规则将请求转到Real Server,最终落到某个EndPoint(Pod)上,这个过程就是负载均衡
然而Headless Service工作起来自主性更加直接,它主要应用在以下两个场景中
第一种:自主选择权,有时候 client 想自己来决定使用哪个Real Server,可以通过查询DNS来获取 Real Server 的信息。
第二种:Headless Service 的对应的每一个 Endpoints,即每一个Pod,都会有对应的DNS域名,这样Pod之间就可以互相访问。
根据以上网上抄来的内容可得知,这第二种场景,就是我们使用StatefulSet去控制有状态服务节点要用到的
我们通过Headless Service会让服务中的每个Pod都会得到集群内的一个DNS域名
格式为(service name).$(namespace).svc.cluster.local
也就是说在pod中去ping一下这些域名,是可以解析为pod的ip并ping通的
这样在我们集群的中其他应用里去访问这些pod的时候,就可以直接通过这个域名来访问,而不用苦恼于变幻莫测的pod IP了
我们在后面部署起Redis的节点之后会进去试一下
科普完毕 我们继续
真的开始配置Headless Service了
还是打开YAML导入窗口
输入以下内容
apiVersion: v1
kind: Service
metadata:
name: redis-headless-service
namespace: redis
labels:
app: redis
spec:
ports:
- name: redis-port
port: 6379
clusterIP: None
selector:
app: redis
appCluster: redis-cluster
---
apiVersion: v1
kind: Service
metadata:
name: redis-service
namespace: redis
labels:
app: redis
spec:
ports:
- name: redis-port
protocol: "TCP"
port: 6379
targetPort: 6379
selector:
app: redis
appCluster: redis-cluster
---
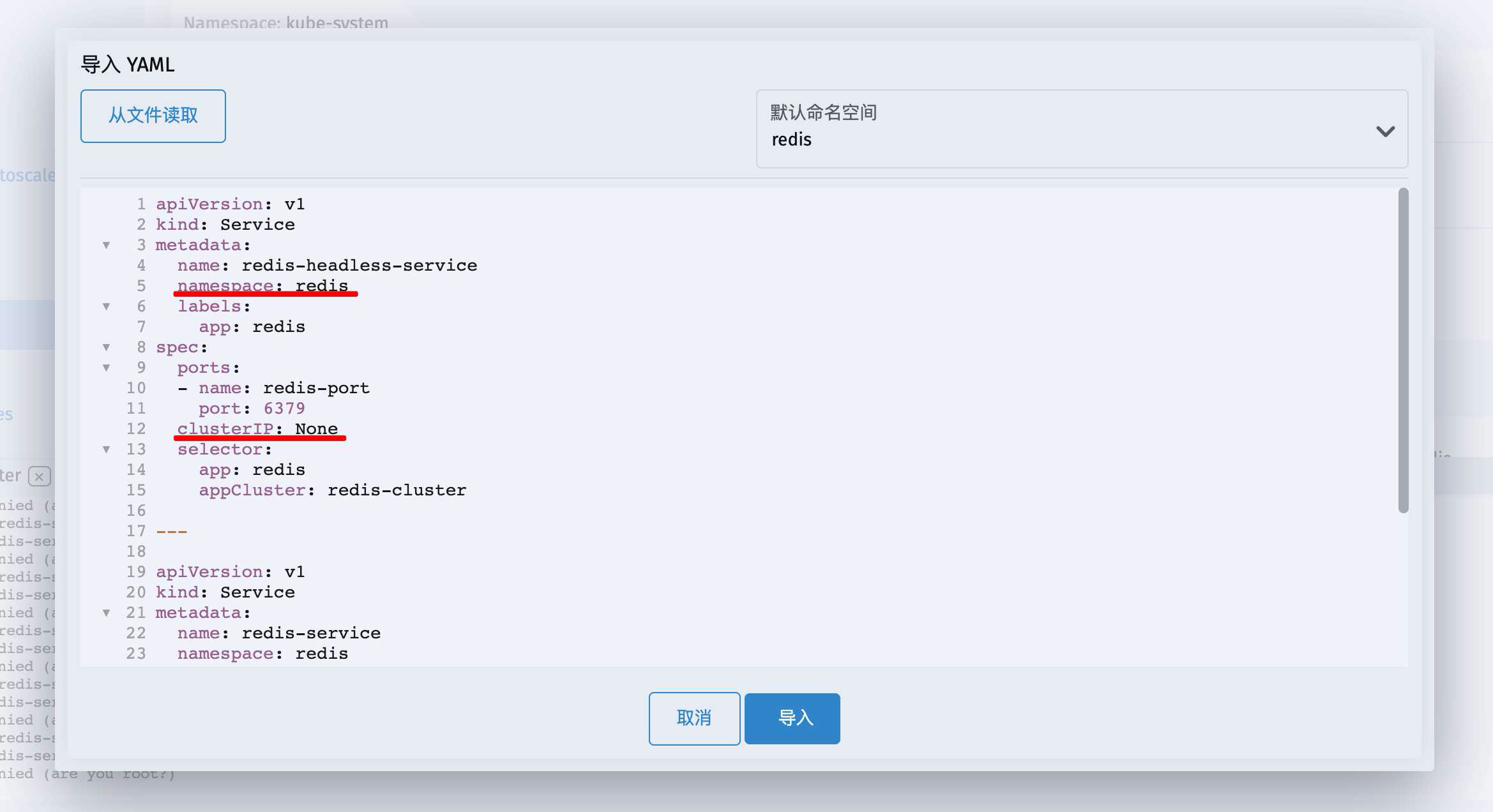
这里注意一下 命名空间用的是redis
并且在 clusterIP: None 这里指定了headless 的特性
这里不光配置了一个Headless Service 还同时创建了一个ClusterIP Service提供给别的应用连接使用,例如SpringBoot
导入执行
StatefulSet来了
到了这一步,就是真正创建我们的Redis任务了
依旧是打开YAML导入窗口
输入以下内容
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-app
namespace: redis
spec:
replicas: 6
selector:
matchLabels:
workload.user.cattle.io/workloadselector: statefulSet-redis-redis-app
serviceName: redis-service
template:
metadata:
labels:
app: redis
appCluster: redis-cluster
workload.user.cattle.io/workloadselector: statefulSet-redis-redis-app
spec:
containers:
- args:
- /conf/update-node.sh
- redis-server
- /conf/redis.conf
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
image: redis:6.2.4-alpine
imagePullPolicy: IfNotPresent
name: redis-app
ports:
- containerPort: 6379
name: redis
protocol: TCP
- containerPort: 16379
name: cluster
protocol: TCP
volumeMounts:
- mountPath: /conf
name: conf
- mountPath: /data
name: redis-storage
subPath: redis/node
volumes:
- configMap:
defaultMode: 493
name: redis-cluster
optional: false
name: conf
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: redis-storage
namespace: redis
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Mi
storageClassName: nfs-redis #此处选择用哪个存储类
内容有点多 稍微说明一下
这里创建了一个6节点(replicas: 6)的StatefulSet任务
名字就叫redis-app(redis-app)后面会根据命名自动生成pod的名字(redis-app-0 … redis-app-5)
- containers: – args: 这里面是容器启动时执行的命令
我们在 redis-server 命令后带上了参数 – /conf/redis.conf 也就是挂上了前面配置映射里面的配置文件redis.conf -
上面还有一个命令 – /conf/update-node.sh 是为了在容器节点(pod)启动时执行一下拿到pod的IP地址,随后要将IP地址写入到 /data/nodes.conf 文件中记录下来,这一部分非常重要 要是缺少了这个,我们的redis集群节点在重生的时候就会与集群失联了
-
image这里 依旧需要注意镜像的选择
-
imagePullPolicy是镜像拉取规则,这里IfNotPresent是说拉过就别再拉了
-
ports里面设置两个端口,分别是redis服务端口和redis集群操作用的端口(6379,16379)
-
volumes下面有两个卷
一个叫conf(name: conf)它引用了之前创建的名叫redis-cluster(name: redis-cluster)的configMap
此处的defaultMode: 493也不能丢掉 这是挂载的映射文件操作权限
| 动作 | 权值 | 解释 |
|---|---|---|
| read | 4 | 可读 |
| write | 2 | 可写 |
| execute | 1 | 可执行 |
这里如果没有设置权限的话,默认是不可执行的,也就无法自行上面获取和写入IP地址的命令
另一个卷是redis-storage(name: redis-storage)它就是我们之前费老大劲部署的nfs服务中的存储卷
- volumeMounts指的是卷的挂载信息
-
name: conf这条的挂载路径是容器内的/conf里面的文件(mountPath: /conf) 这里和前面的containers: – args:里面指定的conf文件路径是一致的
-
name: redis-storage这里挂载的容器内的/data里面的文件
-
subPath: redis/node是指NFS服务器下面那块硬盘路径下的子路径,这里面存储的就是redis集群节点的信息了,其中包括我们前面ConfigMap那里通过执行命令来写入的本节点IP信息以及集群的信息
-
volumeClaimTemplates就是前面提到的PVC模板了
通过它我们就能让StatefulSet自动去创建PV,PVC
下面storageClassName里面指定了我们用到的StorageClass存储类
也就是前面创建的那个 它叫 nfs
accessModes的模式有三种
- ReadWriteOnce:可读科写,但支持被单个node挂载
- ReadOnlyMany:可以以读的方式被多个node挂载
- ReadWriteMany:可以以读写的方式被多个node挂载
我们用的是ReadWriteOnce,也就是一个redis的节点(node)自己独享一个PV,PVC
- resources下面还可以指定一下初始分配的存储空间大小以及上限
最后,导入执行
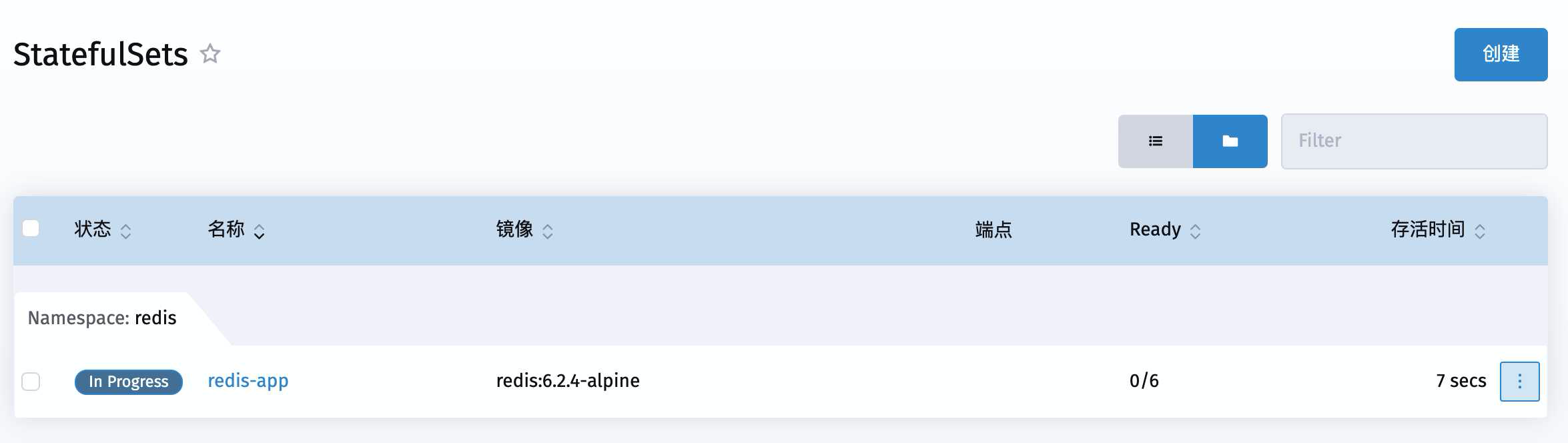
结果一直在 In Progress
出问题了
坑坑坑
这里出现了一个前期部署K3s集群的时候就留下来的坑
我们点开redis-app来看看
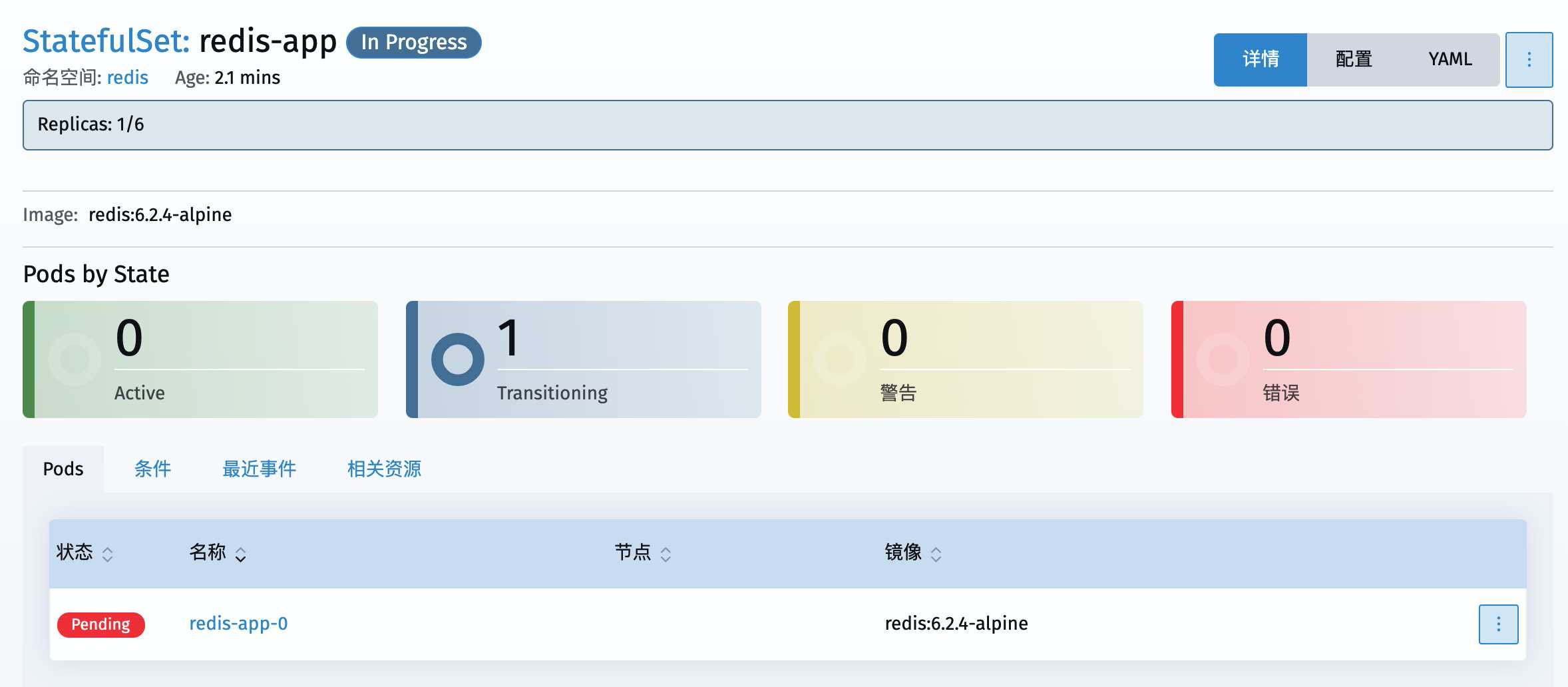
发现这第一个节点redis-app-0就没部署成功
继续点进去看
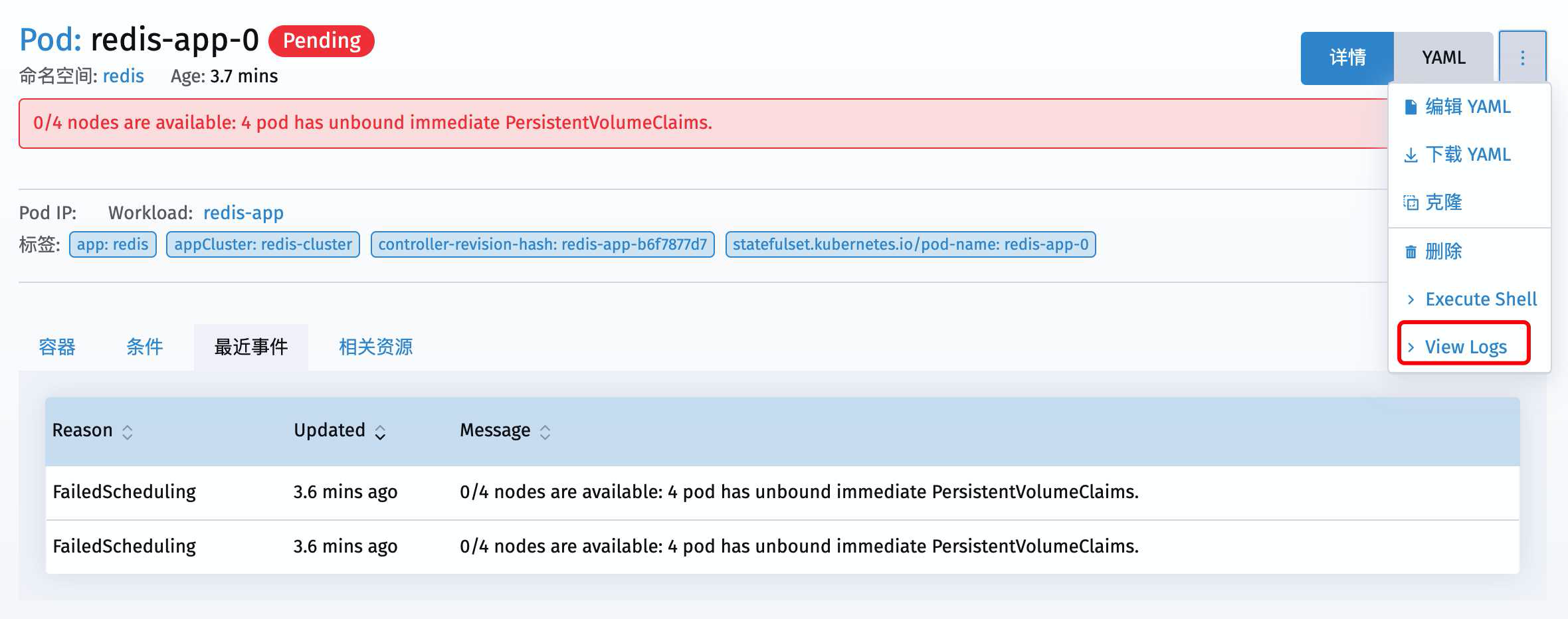
可以看到提示错误在 PersistentVolumeClaims 这里
一路追杀到PVC目录下面发现果然第一个PVC就没成功
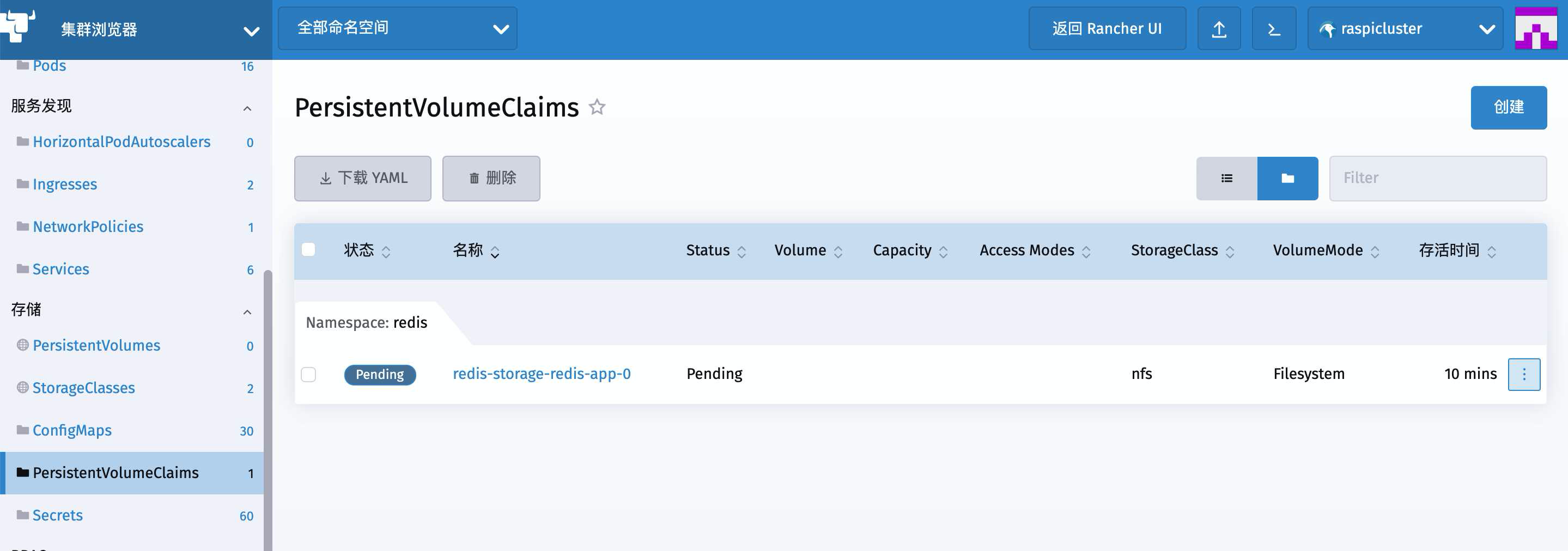
继续点开 redis-storage-redis-app-0 然后查看最近事件
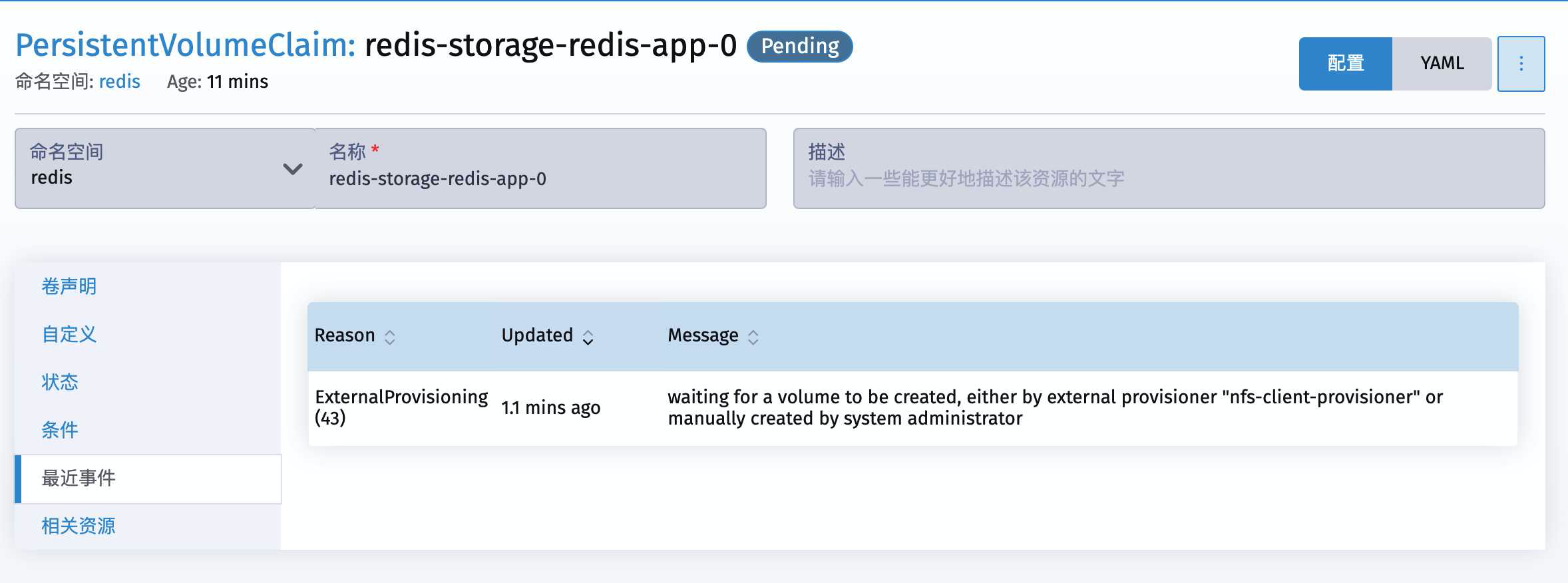
说是等待nfs-client-provisioner或者管理员来创建volume
这就很不科学,因为我们的nfs-client-provisioner就是用来自动创建PVC和PV的
既然没成功肯定是nfs-client-provisioner这里有问题
所以我们继续一路追杀到了 nfs-client-provisioner 这边
从左侧菜单里的Deployments找到我们在上一篇文章中出创建的这个nfs-client-provisioner
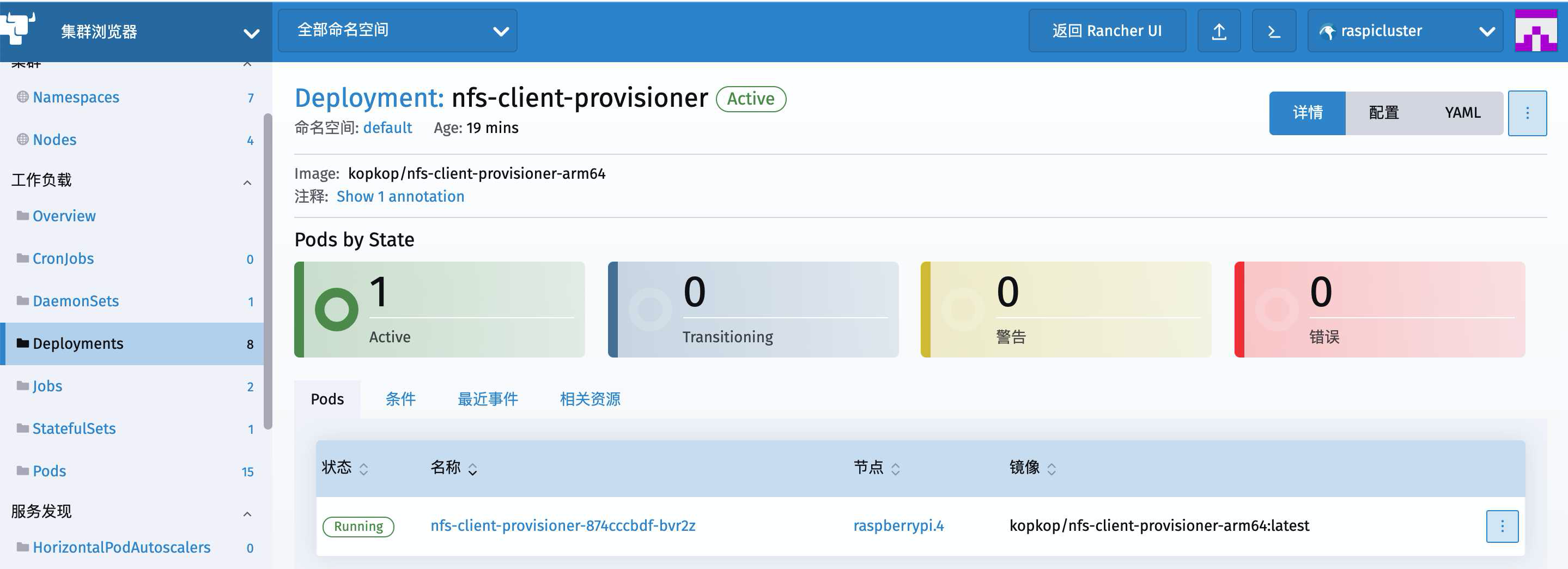
能看到它倒是活的好好儿的,可丫为什么不干活儿呢
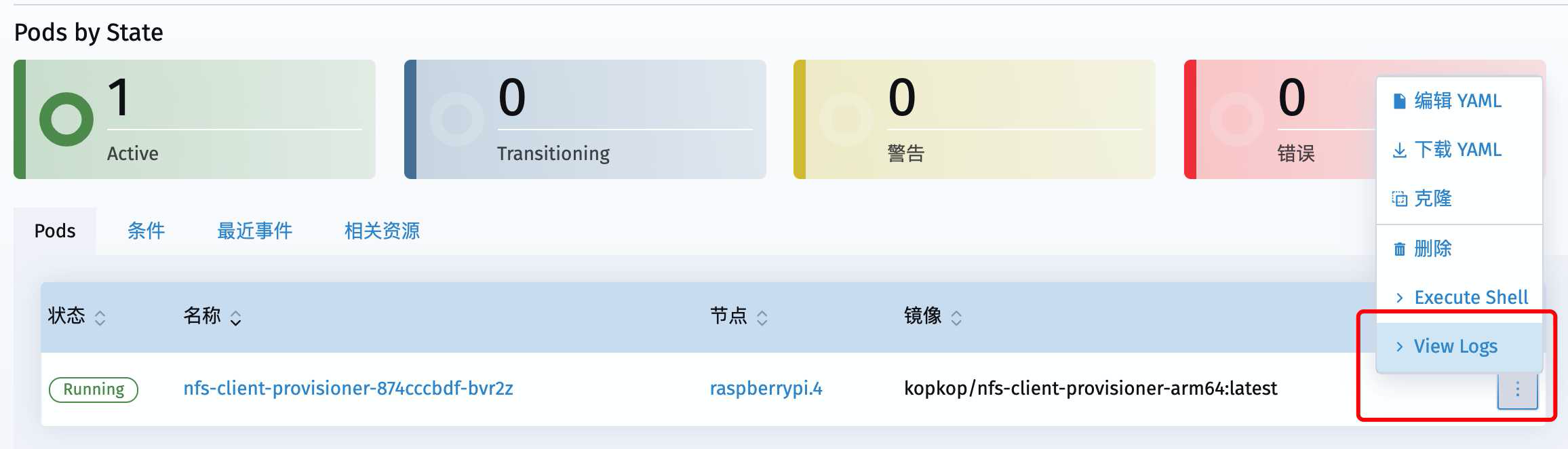
点击右侧三个点儿,打开菜单去找日志
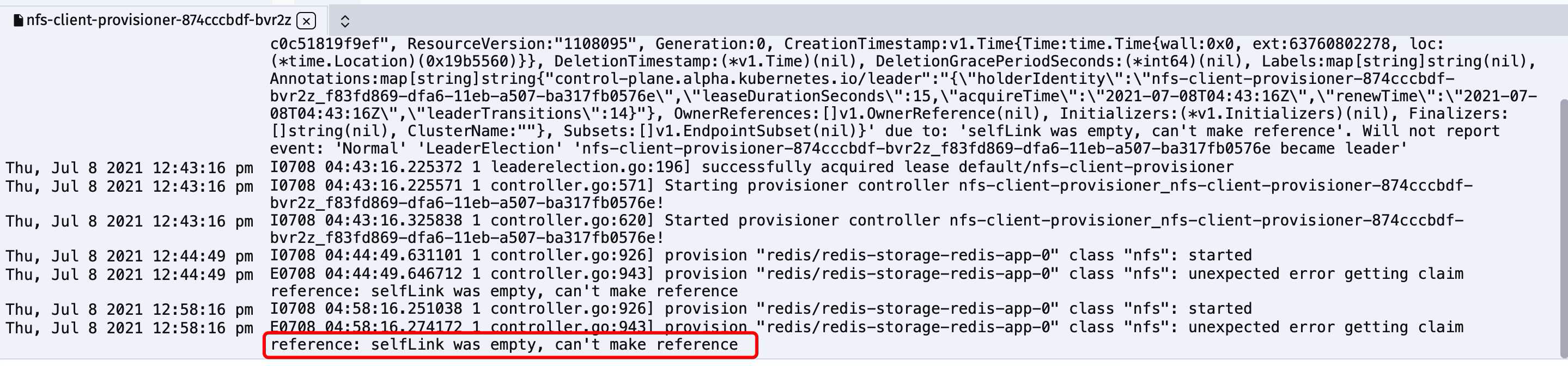
selfLink was empty, can’t make reference
破了案了
直接贴上来一个stackoverflow上面网友们就这个问题的挣扎与迷思
Kubernetes nfs provider selfLink was empty
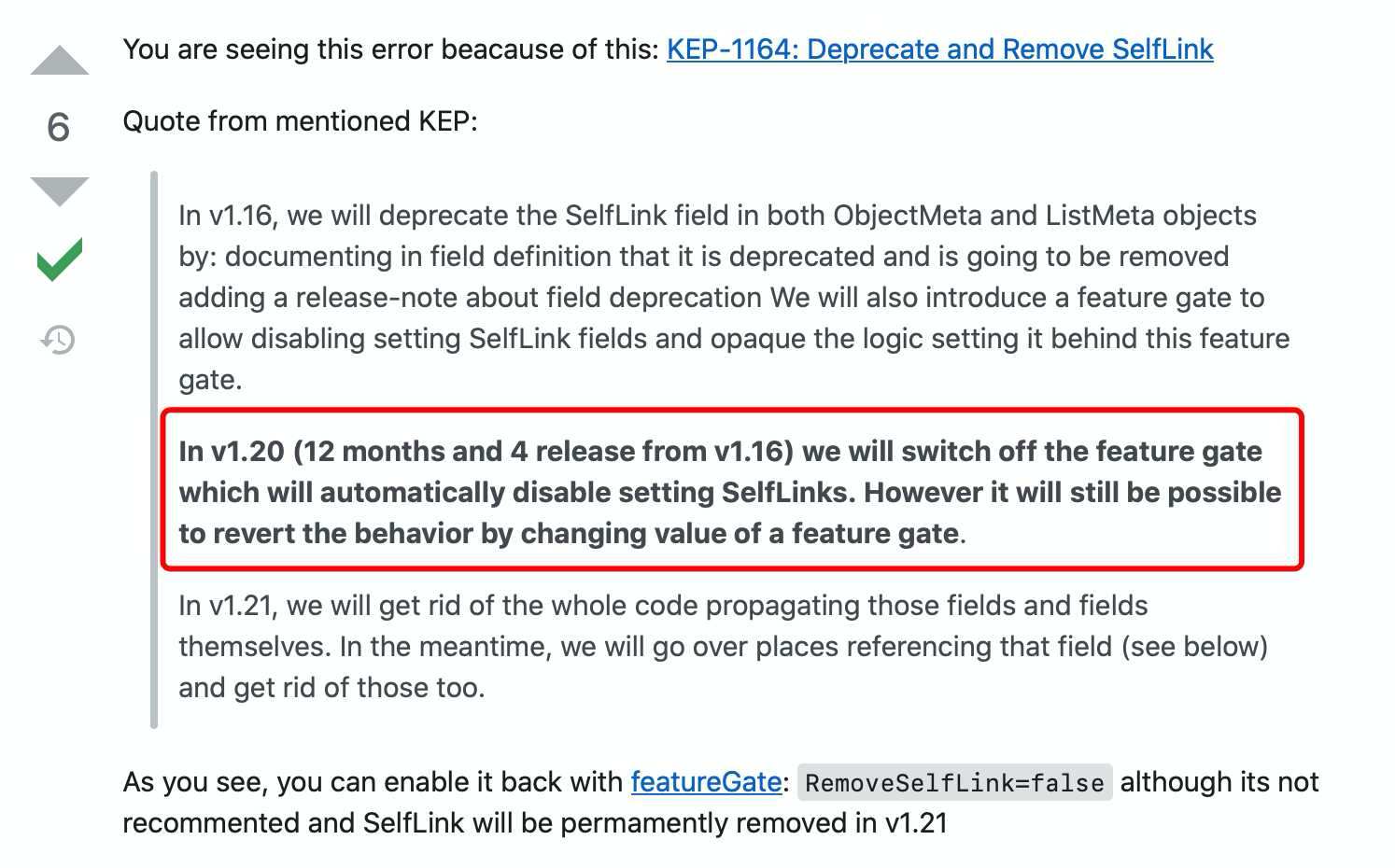
也就是说,错误中提到的SelfLinks功能在Kubernetes v1.20之后的版本中默认已经被关闭了
查看一下我们Kubernetes Dashboard首页上能看到的版本
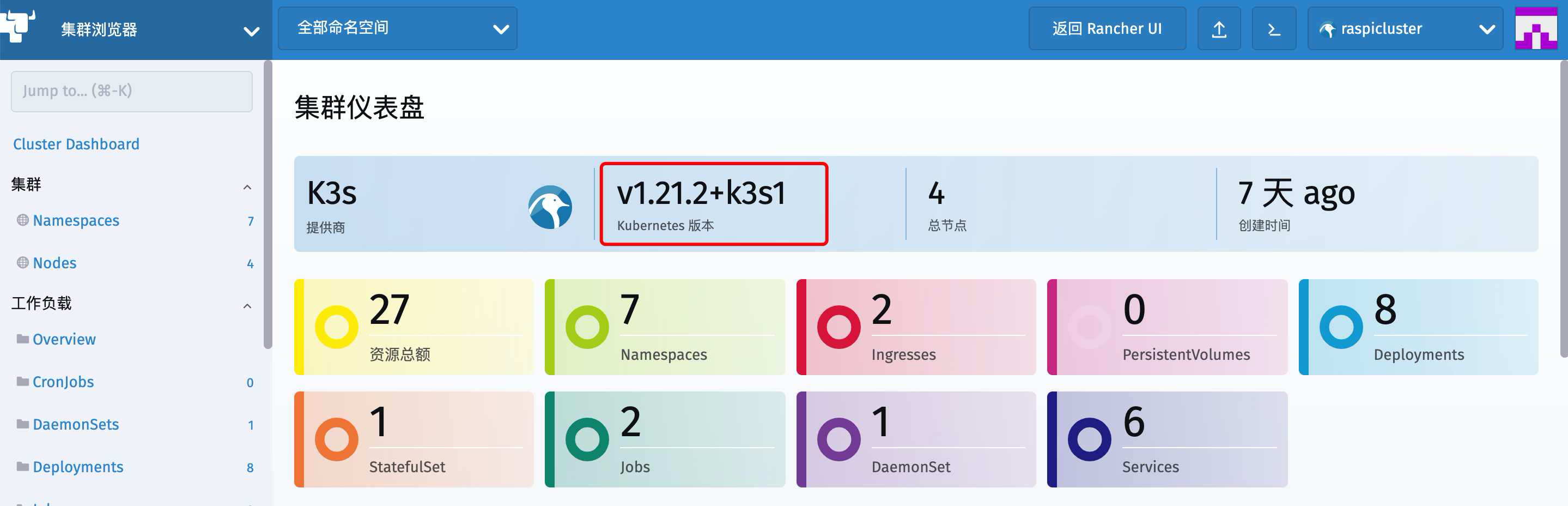
可以看到当前版本是 v1.21.2+k3s1
我们的nfs-client-provisioner工作时要使用SelfLink,然而SelfLink默认就已经关了,因此正是这个原因导致报错
问题找到就好解决了
如果是kubernetes的集群,我们只要找到对应的配置文件加上相关的配置就好
vi /etc/kubernetes/manifests/kube-apiserver.yaml
找到这里
spec:
containers:
- command:
- kube-apiserver
在下面添加一行
–feature-gates=RemoveSelfLink=false
spec:
containers:
- command:
- kube-apiserver
- --feature-gates=RemoveSelfLink=false
然后应用一下就可以了
kubectl apply -f /etc/kubernetes/manifests/kube-apiserver.yaml
然而这并不适用于我们的K3s集群
我们要做的是下面两种方式
第一种 从一开始就配置好
回到我们遥远的第二篇文章
4台RaspberryPi4B搭建K8s(K3s)容器集群(二)部署K3s集群
在使用K3S官方脚本进行安装这里
启动Master节点的时候就颇具前瞻性的加入这个启动参数
像这样
curl -sfL http://rancher-mirror.cnrancher.com/k3s/k3s-install.sh | INSTALL_K3S_EXEC=" --kube-apiserver-arg=feature-gates=RemoveSelfLink=false" INSTALL_K3S_MIRROR=cn K3S_NODE_NAME=pi1 sh -
–kube-apiserver-arg=feature-gates=RemoveSelfLink=false
也就是说如果确定要使用NFS服务的话,从一开始直接加上就好
但是一开始我们图省心,用了AutoK3s来部署K3s集群
这里其实也是有个地方可以添加最初的参数的
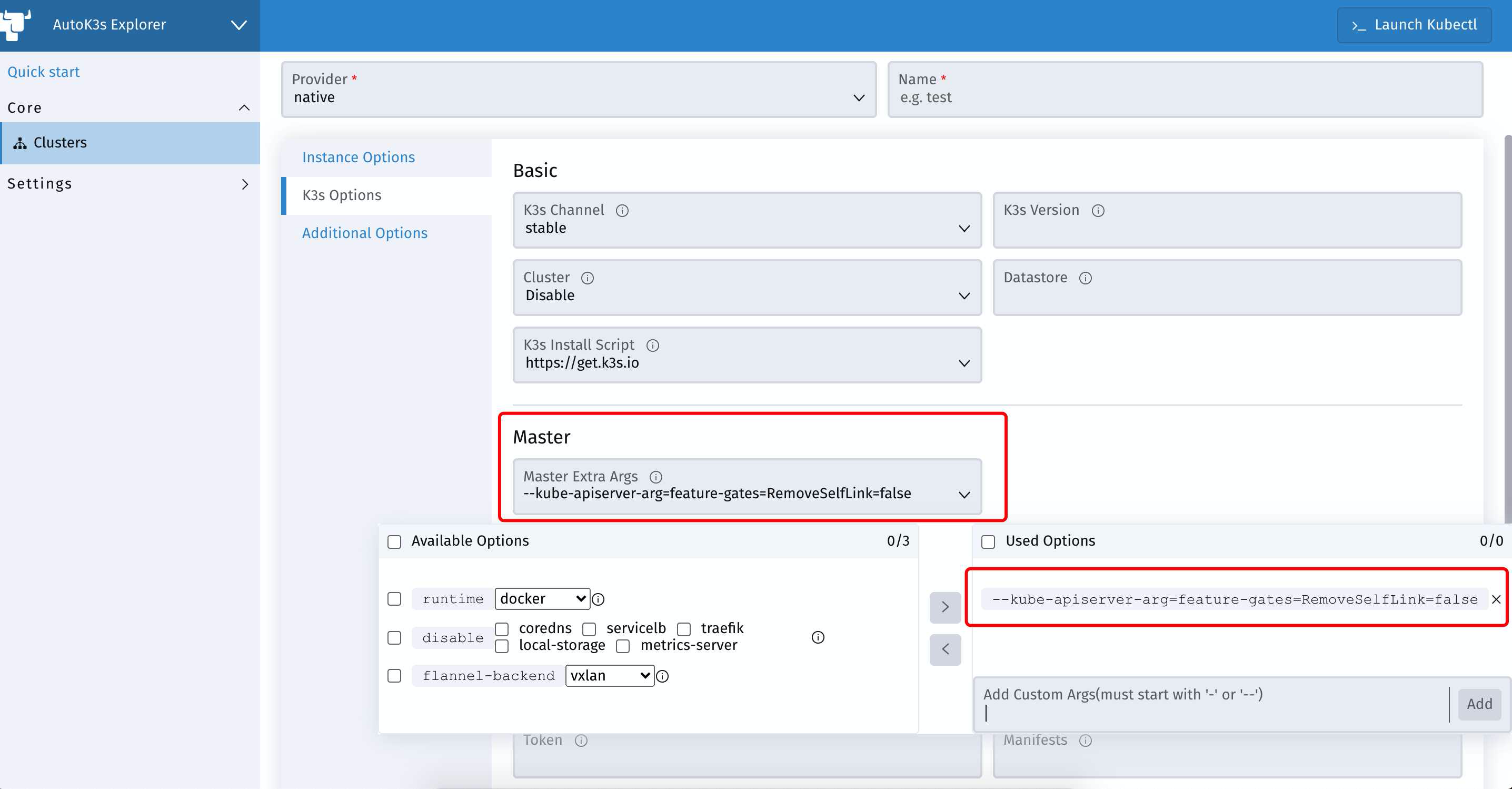
创建新的集群时,点开K3s Options 在Master下添加一个Custom Args就好了
第二种
对于我们一路摸着石头跑过来的情况,并不能未卜先知的预料到这里的问题
那么在集群已经运行起来的情况下,就需要向修改K8s的yaml文件一样来修改我们K3s的yaml配置文件
只不过这里并不是像K8s那样跑一段yaml把配置注进去就行
而是需要从K3s服务的启动配置上下手(k3s.service)
具体做法如下
直接来到K3s的Master节点主机(树莓派集群的零号机)上去编辑k3s.service文件
vim /etc/systemd/system/multi-user.target.wants/k3s.service
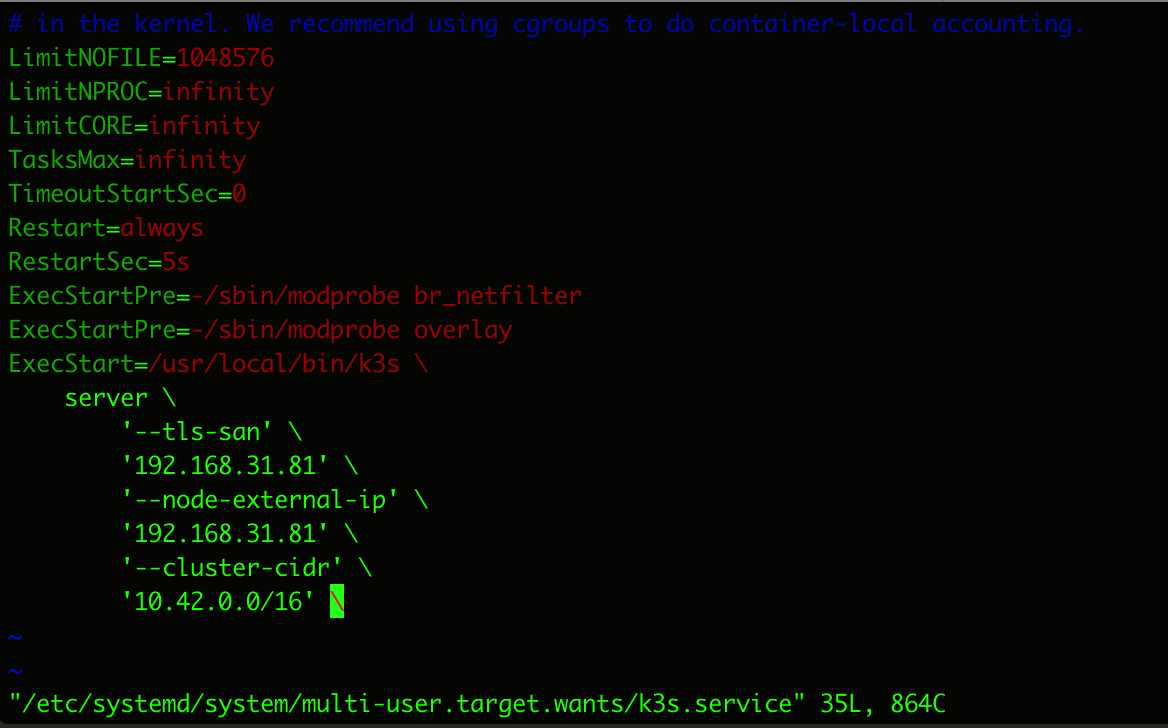
找到 ExecStart 的内容,加上下面两行
‘–kube-apiserver-arg’ /
‘feature-gates=RemoveSelfLink=false’ /
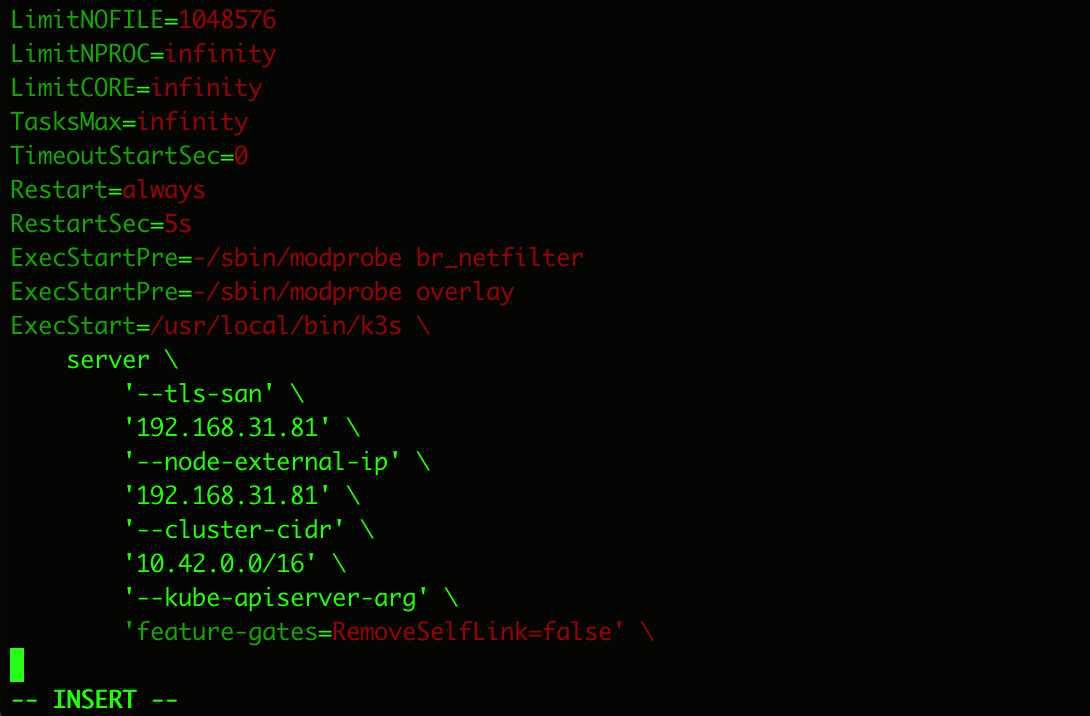
随后记得daemon-reload
systemctl daemon-reload
再重启k3s.service
systemctl restart k3s.service
这样就可以了
回到 dashboard 下 找到刚才pending 的StatefulSet重新部署
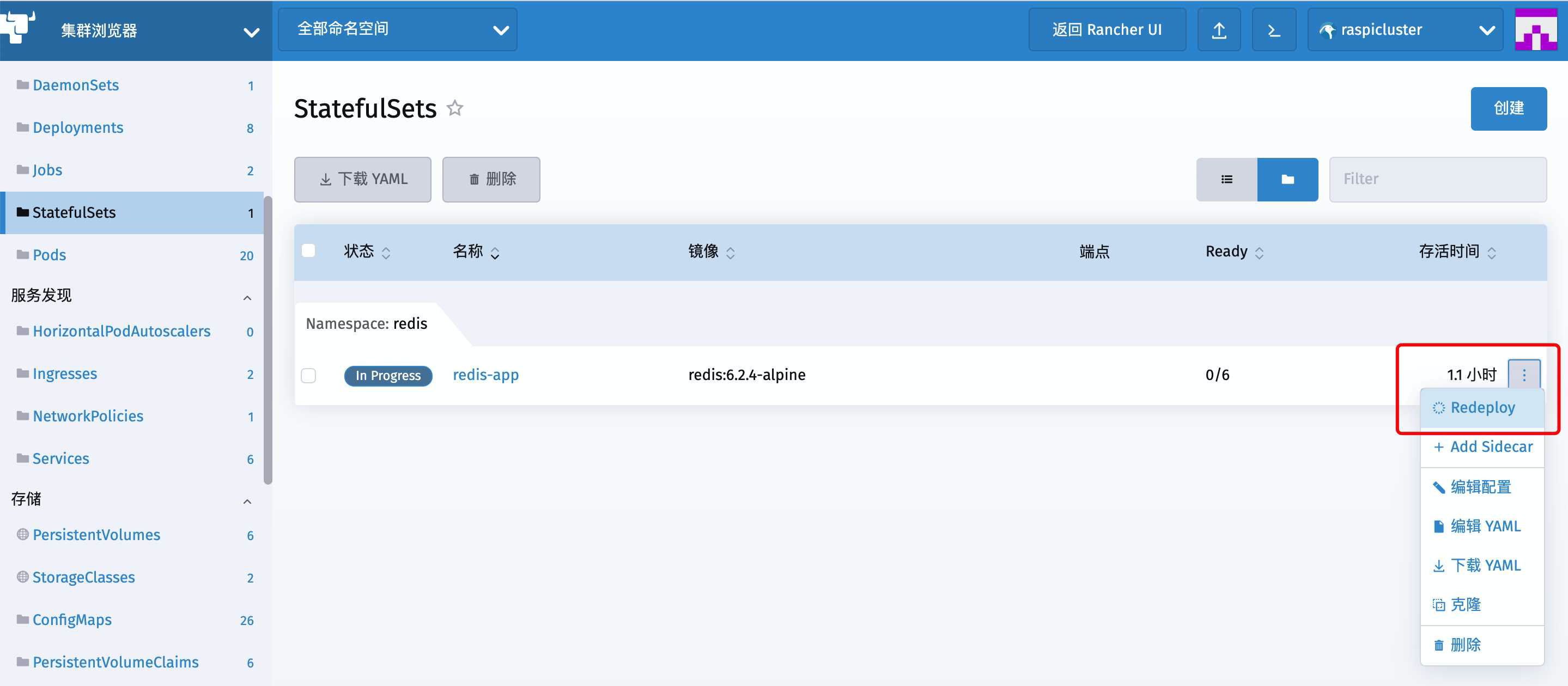
这下成功了

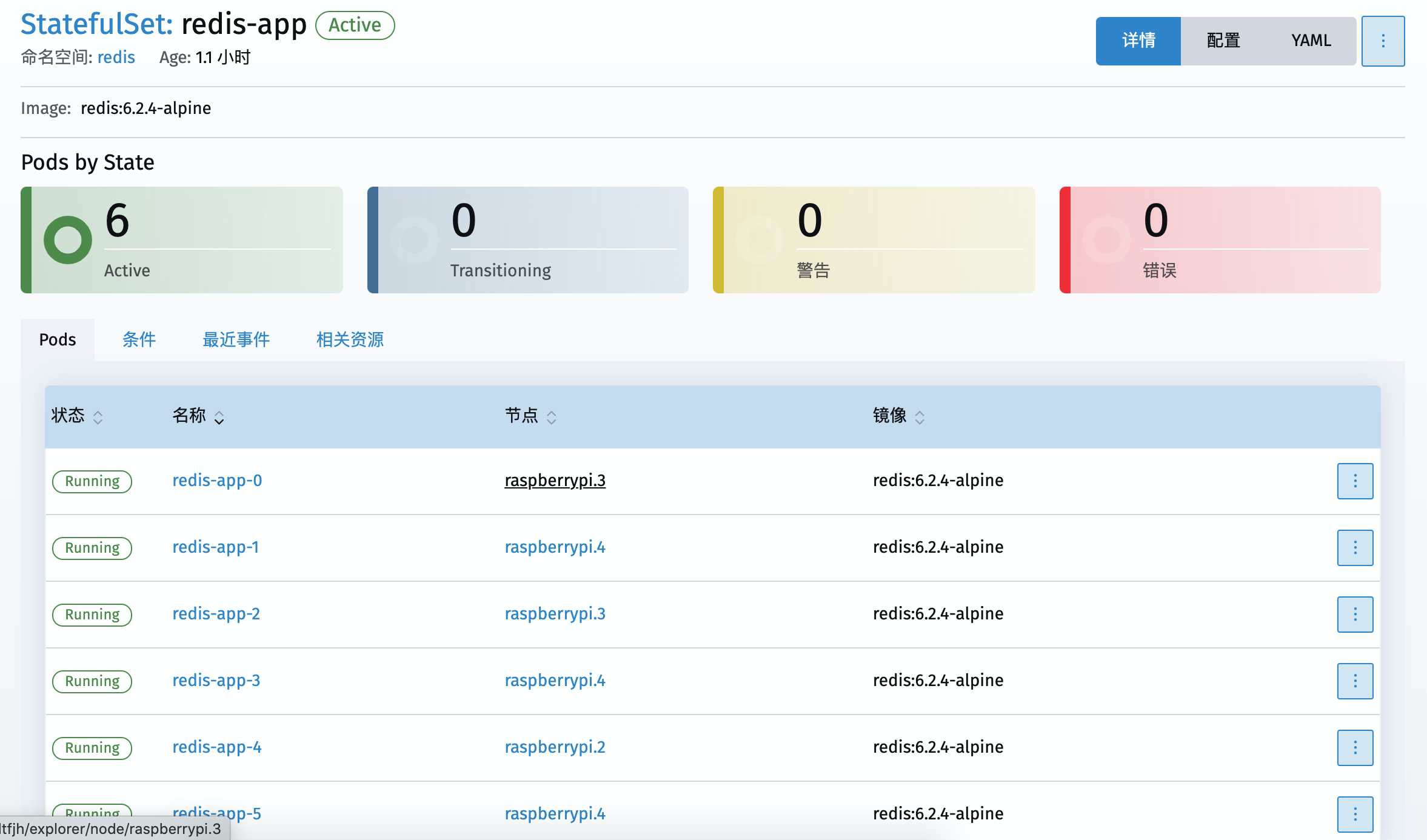
点进去能看到 自动部署了6个redis的节点
序号也是固定顺序的 0 – 5
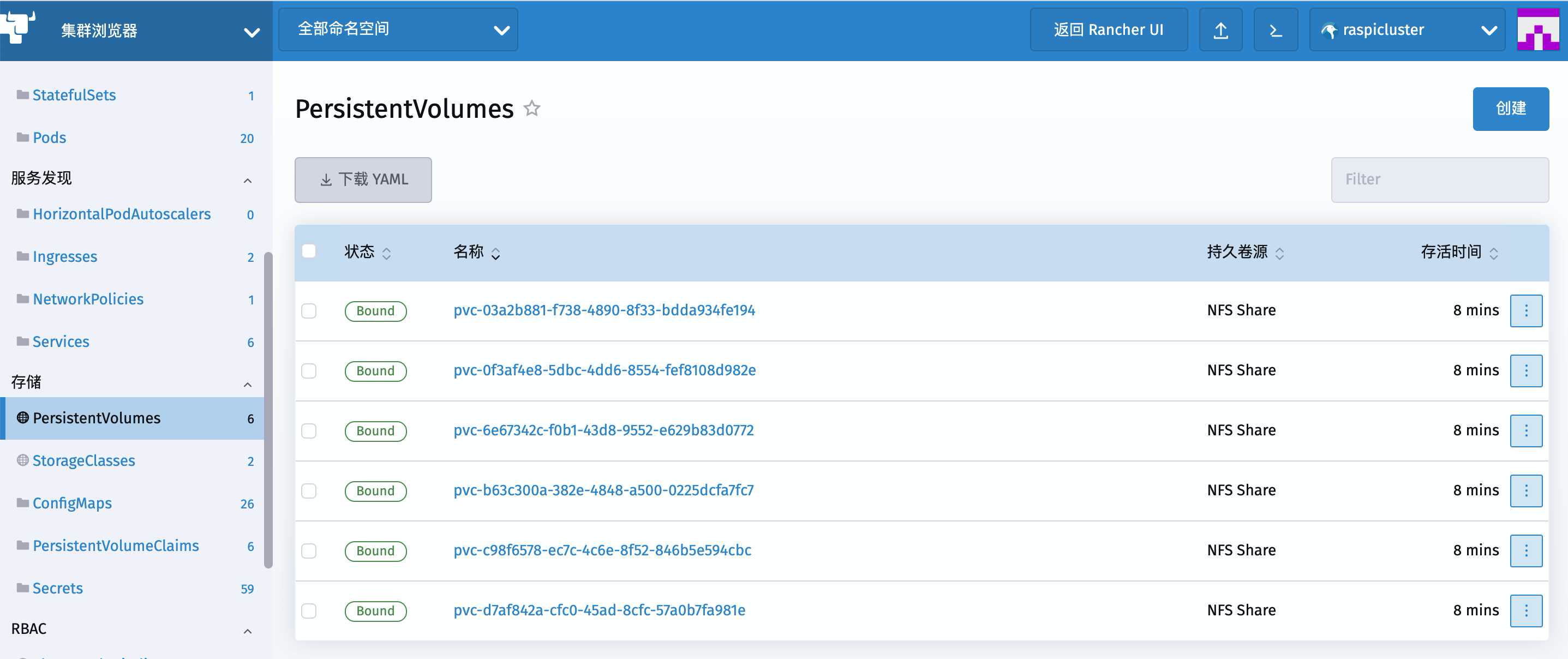
点击左侧菜单的PersistentVolumes
可以看到NFS服务已经自动创建了6个PV出来
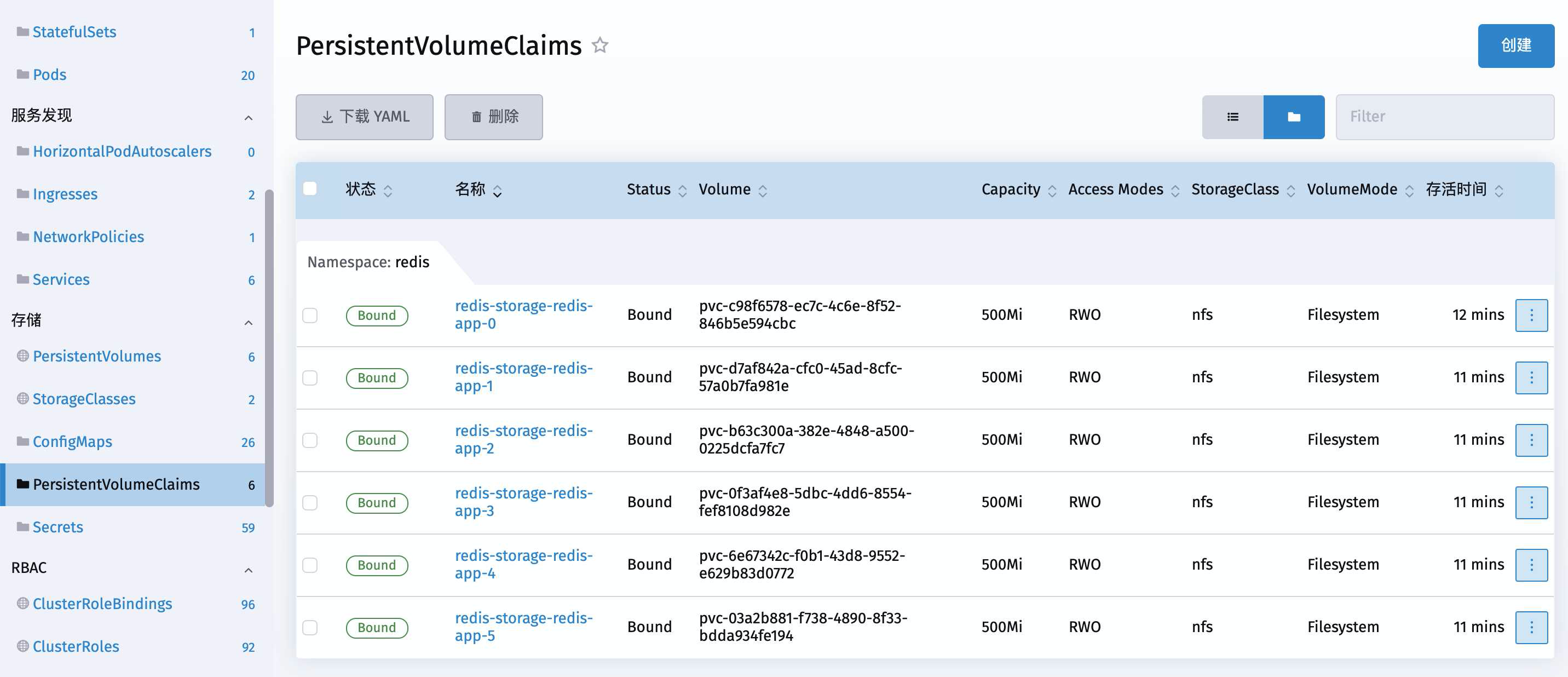
再来到PersistentVolumeClaims这里
可以看到对应的也自动创建了6个PVC出来
同时我们来到NFS服务器(贰号机)下面的NFS路径下
可以看到对应的文件已经在这里出现了
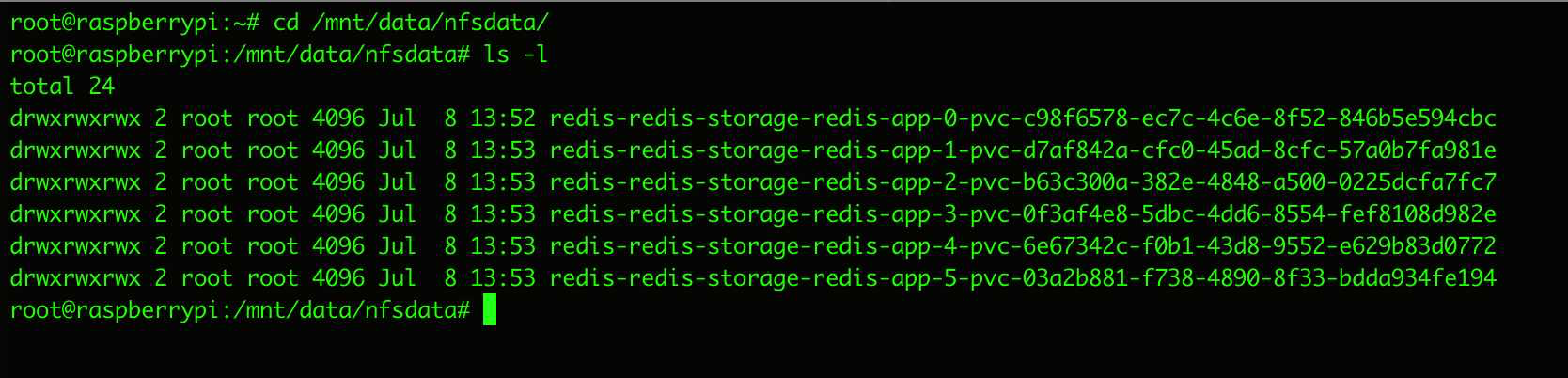
然后
突如其来的科普回顾
既然已经看得到PV创建出来的文件了
在这里停下思考一下,这些文件的删除操作是在什么时候进行的呢?
——回收策略 Reclaim Policy
这就是上一篇文章我们创建StorageClass存储类时的配置内容了
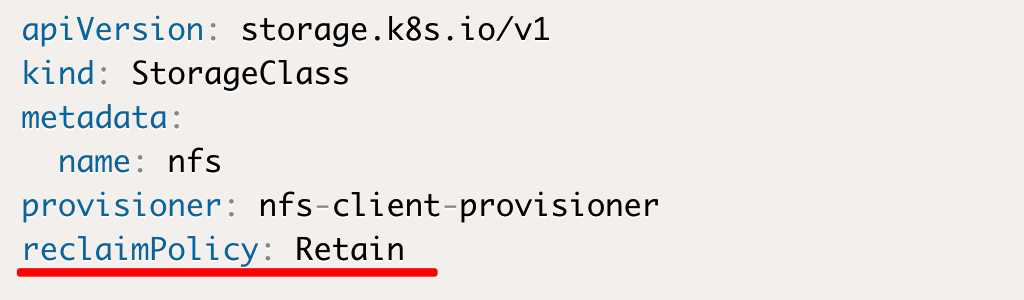
这里我们用了Retain
首先我们要知道 PV 与 PVC 是一一绑定的,我们在上面的Dashboard中也可以看到绿色的Bound字样,这就说明PV与对应的PVC已经互相绑定好了
同时PV的删除操作并不是说删就删的,其中一个前提条件就是需要先”解绑”
也就是当PVC被删除的时候,它对应的PV会由绑定状态(Bound)变为释放状态(release)
然后PV才可以被删除
至于PVC被删除之后,它对应的PV要不要删,怎么删
这就是由 StorageClass的回收策略 Reclaim Policy 来控制了
这里的配置一共有两种方式
DELETE 这是默认方式,这会导致当删除PVC时,由StorageClass自动生成的PV也会直接被删除,而这个PV可能已经保存了用户不想删除的数据,比如Redis的数据,然而说没就没了。
Retain 因此我们采用这种方式。当PVC被删除的时候,对应的PV被标记为released. 此时该PV已经被解绑释放,同时之前的数据依旧保存在该PV上,只是该PV不可用,需要手动来处理这些数据并删除该PV。这样一来重要数据的回收工作就由管理员来手动进行了。
实际上我们StatefulSet下面的节点(pod)在重生(重新生一个)的时候,相当于新来的克隆人从工厂的办公室去捡起了前面死掉的那个节点(pod)丢掉的工牌(固定序号)继续用,也就顺理成章的继续使用前任一直在用的PVC和PV继续干活了。
科普之后我们继续,还差一步
Redis的6个节点已经部署成功,最后我们要来到Redis里面用这6个节点组建好Redis集群就可以用了
我们从 Dashboard 上直接用它的命令行操作 按钮在上面
接着来查看一下所有redis节点的IP是什么
kubectl get pods -n redis -l app=redis -o jsonpath='{range.items[*]}{.status.podIP}:6379 {end}'
我们的命令中用命名空间(-n redis)和标签(app=redis)定位到了redis的节点,同时用jsonpath遍历了所有节点的IP(.status.podIP)并且在后面手动加上端口号(:6379)
最后得到了这样的格式
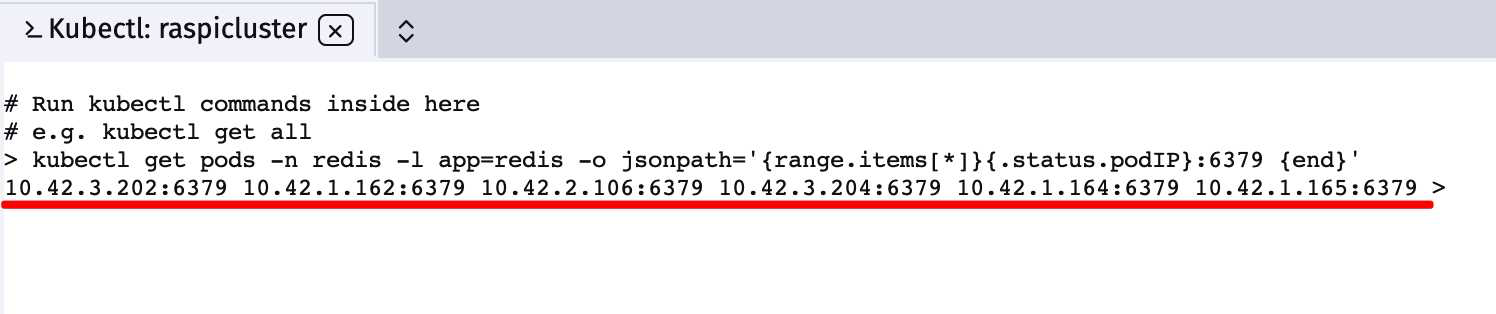
10.42.3.202:6379 10.42.1.162:6379 10.42.2.106:6379 10.42.3.204:6379 10.42.1.164:6379 10.42.1.165:6379
我们用以上的IP+端口+空格的格式用在redis的–cluster create命令中就可以了
直接钻进其中一个节点去执行redis命令
kubectl exec -it redis-app-0 -n redis -- redis-cli --cluster create --cluster-replicas 1 $(kubectl get pods -n redis -l app=redis -o jsonpath='{range.items[*]}{.status.podIP}:6379 {end}')
说明一下 参数中的
–cluster-replicas 1
是redis集群的策略 这里是比例
1指的是 1:1来分配主从节点6节点 分配出来就是3主3从了
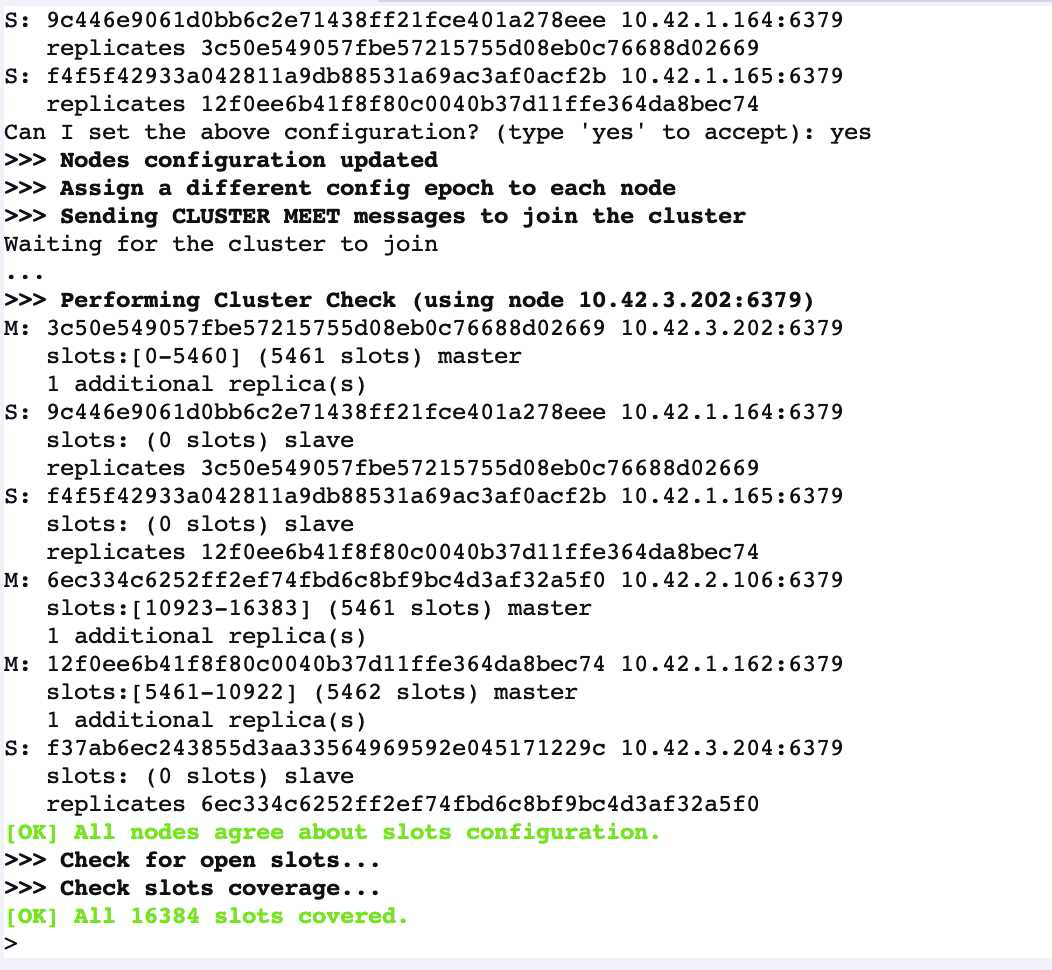
中间输入一次yes
最后可以看到redis集群建立成功了
再次进入节点的redis环境下去查看一下集群是否正常工作
kubectl exec -it redis-app-0 -n redis -- redis-cli -c
注意操作redis集群的时候 最后有个-c
进入redis之后 查看一下集群
cluster nodes

能看到6个节点已经meet过彼此并且开始工作了
set值试一下
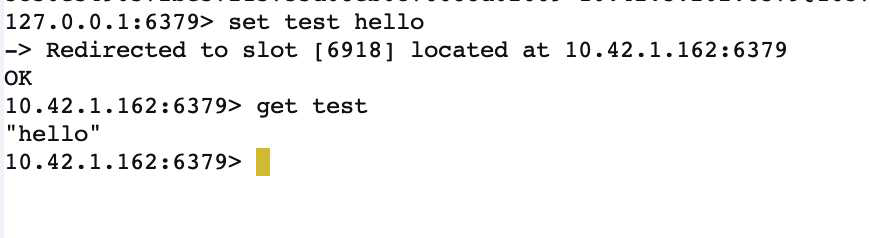
一切正常,槽儿(slot)的分配也很顺利
——存档点
横线的内的这里是坑的开始
坑坑坑 ——现身说法
看上去一切顺利
这里引出一个思考,我们既然是通过节点IP(容器IP)建立的redis集群,那么节点(pod)死掉又重生的时候,它的节点IP肯定也随之改变了,那么redis集群还会找到它嘛?
这里就是前面反复提到的ConfigMap里面的那条命令起到了至关重要的作用
update-node.sh: |-
#!/bin/sh
REDIS_NODES="/data/nodes.conf"
sed -i -e "/myself/ s/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}/{POD_IP}/"{REDIS_NODES}
exec "$@"
我们接下来本着求真务实的科研态度,主动跳入坑中来现身说法
假装回到前面部署StatefulSet 尝试把命令行下面的
- /conf/update-node.sh
这一行给注释掉
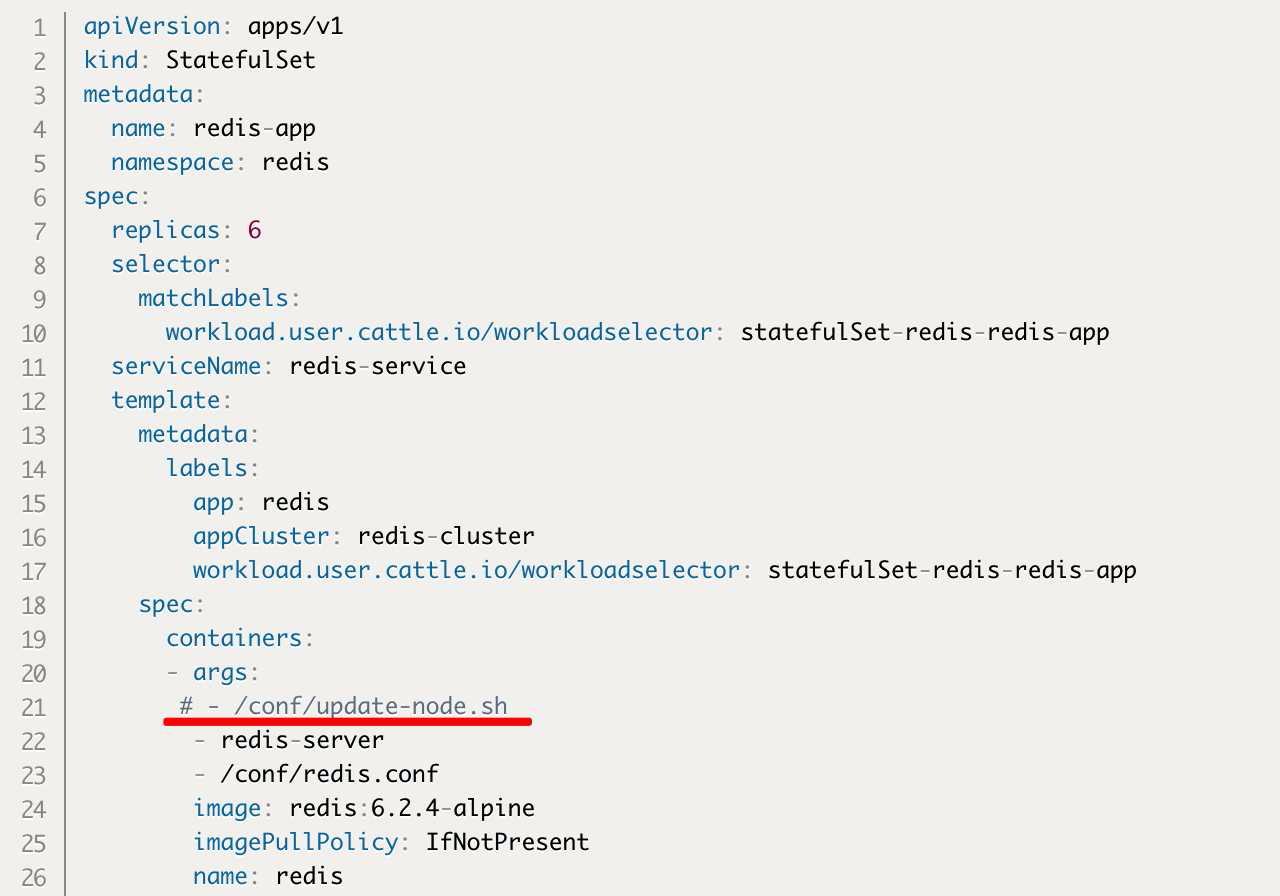
接下来我们假装回到 存档点 那里
就是刚才往组建好的redis集群里面set数据这里
然后我们接着测试集群的工作是否正常
我们看到刚才set数据的时候 located到了 10.42.1.162 这个节点上
查看一下pod信息得知这个节点是redis-app-2
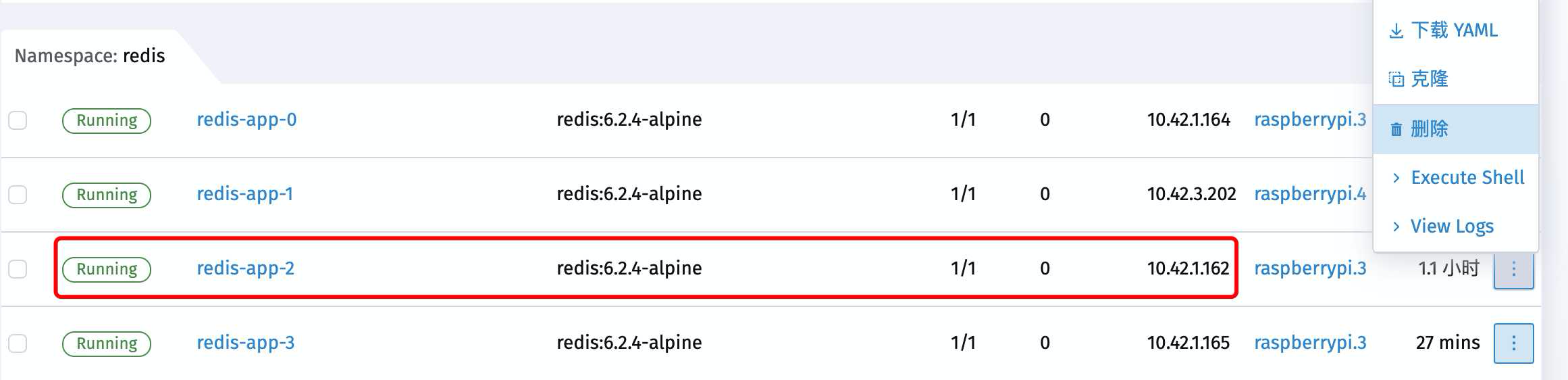
现在直接干掉它
立刻这个节点就terminating随即creating container最后Running起来了
新人来旧人去,就只在一瞬间 然而节点的IP地址确实改变了
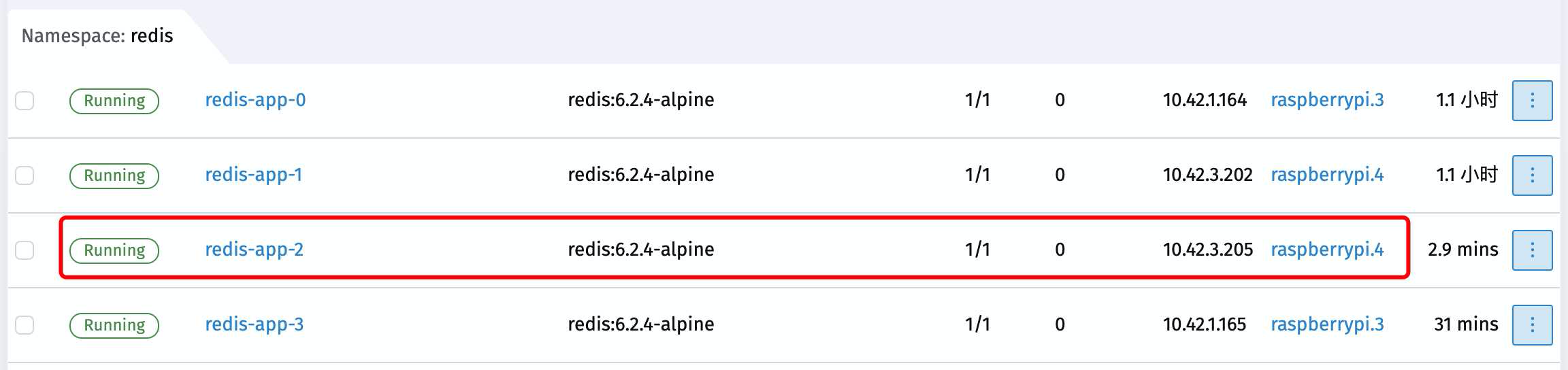
我们继续回到刚才打开的Redis的终端上

发现已经被崩出来了
原因是我们刚才在测试set数据的时候 就被located到了 10.42.1.162 上面了
现在 10.42.1.162 死了 自然就崩出来了
那么重新找个节点进入redis集群去看看呢

不对劲…
get 一下刚才的数据

虽然是正常工作
可目前的状况就是 6个节点挂掉了1个 剩下的5个顶上来继续干活
也就是说 重生的节点 失联了
我们来到NFS服务器硬盘内能看到之前创建的6个PVC对应存储文件夹
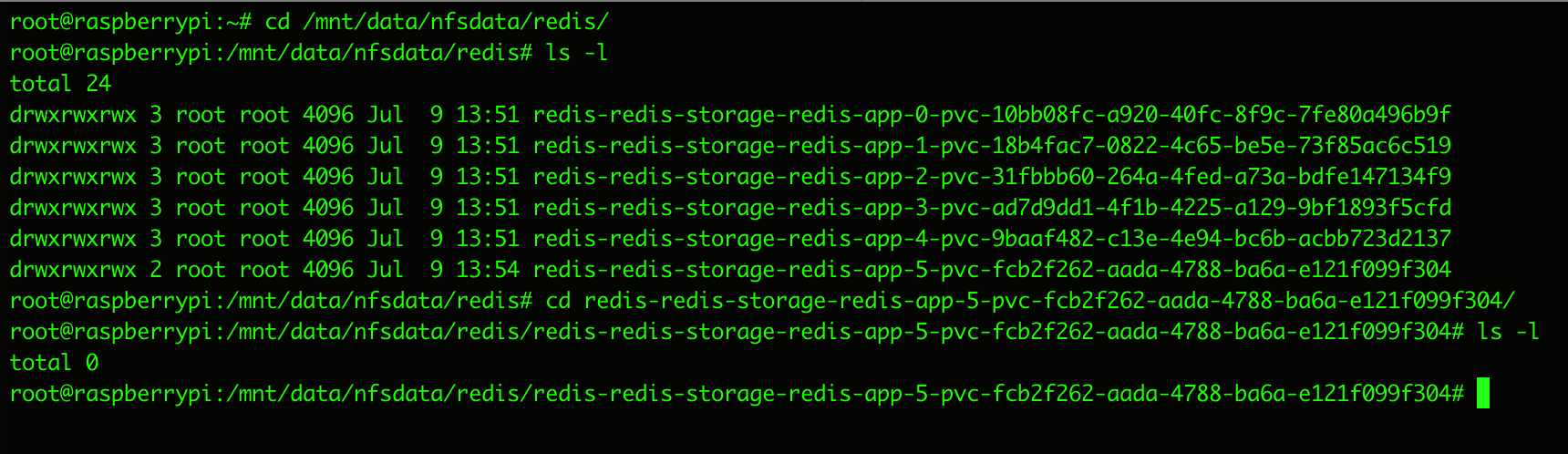
但是随便打开看一下,里面什么也没有
这就问题大了
也就是说,我们的redis节点只要重生,就处于掉线状态没人管了
这可不行
我们回到前面部署StatefulSet那里
假装没有掉进坑中
配置文件上 正常的去加载节点写IP的命令内容
- /conf/update-node.sh
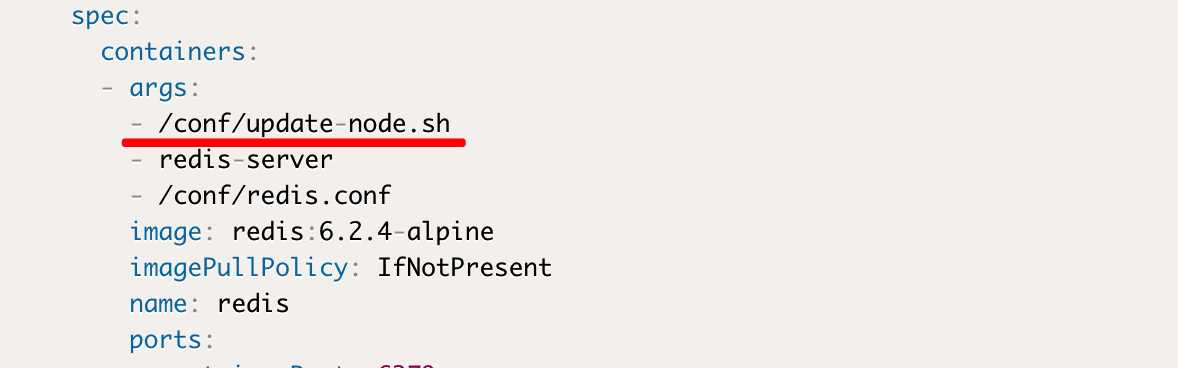
随后继续假装回到 存档点 那里
横线内的这里是坑的结束
我们继续先查看一下redis cluster的情况

一切正常
接着干掉其中一个 10.42.1.218
它是redis-app-5这个节点

然后它重生了 IP变成了 10.42.3.7

我们再去看一下redis集群的信息

可以见到集群信息已经更新了
最后去NFS服务器硬盘里看一眼
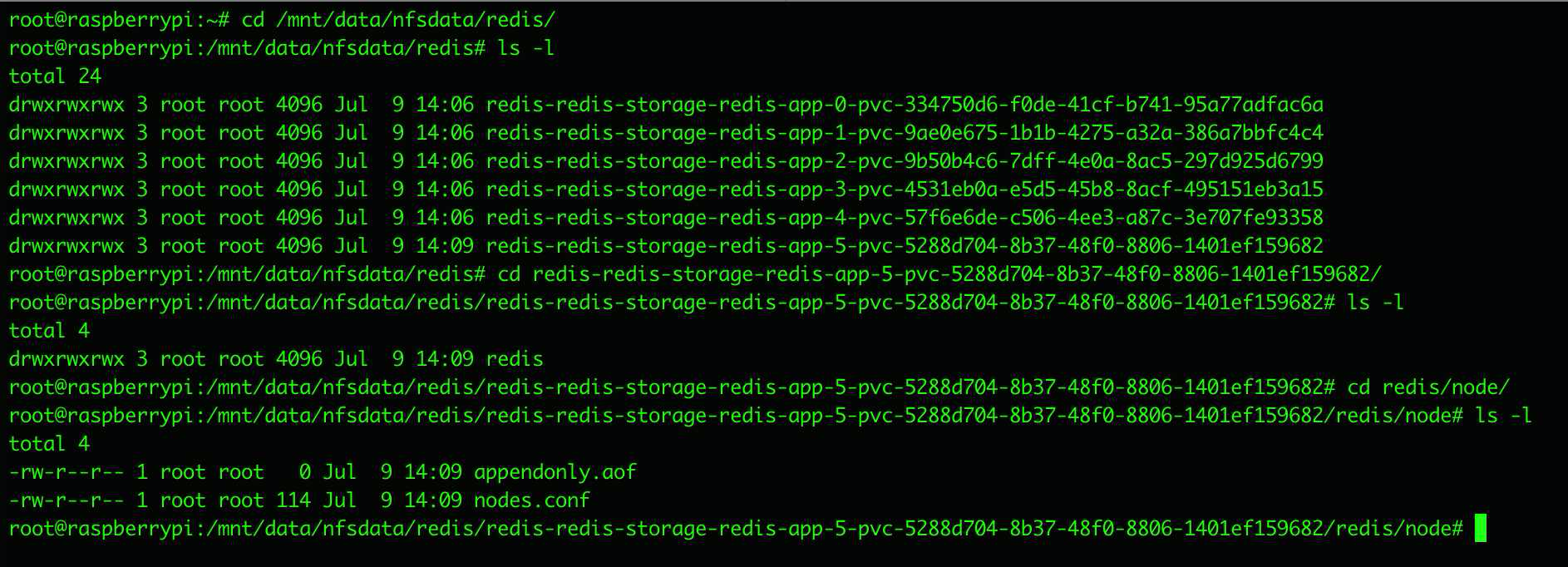
可以看到自动创建的PVC目录下已经有文件了,打开看一下

可看到 myself 这一行的IP 已经被更新了
此时再另外几个节点目录下,这一条的IP也同样被更新了
这样一来就实现了节点重生后,集群信息的同步
好了,K8s集群内搭建6节点(3主3从)Redis集群的工作到此结束
这时候在开发的时候,就可以通过本章科普环节提到的
Headless Service给每个Pod都提供的集群内DNS域名来在集群内部访问到Redis节点了
格式为(service name).$(namespace).svc.cluster.local
我们可以直接访问到指定节点
redis-app-0.redis-service.svc.cluster.local:6379
也可以直接访问Headless Service来实现访问到Redis节点(经过负载)
redis-headless-service.redis.svc.cluster.local:6379
还可去去访问集群IP的那个Service
redis-service.redis.svc.cluster.local:6379
redis-service.redis.svc.cluster.local
redis-service.redis.svc.cluster.local
以SpringBoot为例,我们可以把这里的配置写成这样
# Redis 集群
spring.redis.password=
spring.redis.cluster.nodes=redis-app-0.redis-service.svc.cluster.local:6379,redis-app-1.redis-service.svc.cluster.local:6379,redis-app-2.redis-service.svc.cluster.local:6379,redis-app-3.redis-service.svc.cluster.local:6379,redis-app-4.redis-service.svc.cluster.local:6379,redis-service.svc.cluster.local:6379
spring.redis.cluster.max-redirects=3
spring.redis.lettuce.pool.max-idle=16
spring.redis.lettuce.pool.max-active=32
spring.redis.lettuce.pool.min-idle=8
或者这样直接使用redis-service的集群内部域名而不是用节点域名
# Redis 集群
spring.redis.password=
spring.redis.cluster.nodes=redis-service.redis.svc.cluster.local:6379
spring.redis.cluster.max-redirects=3
spring.redis.lettuce.pool.max-idle=16
spring.redis.lettuce.pool.max-active=32
spring.redis.lettuce.pool.min-idle=8
这样当SpringBoot应用打成镜像部署到K8s集群内的时候就可以通过集群解析成节点IP访问到redis了
具体在 K8s 下 Pod 与 Service 的 DNS 的用法可参考官网
Pod 与 Service 的 DNS
结束